Speed up MongoDB Search Queries
This is blog post is about a problem I faced regarding Search Queries in MongoDB. This is my first blog post so I wanted to start with a simple topic. Feel free to share the feedback.
So, NoSQL databases are growing in popularity and are used by everyone, from big tech giants to independent developers. NoSQL databases support varied storage approaches such as key-value, document-based and many more. These databases allow developers to store documents that contain various data types. For example, consider a movie database where every document contains a movie id and movie title.
{
"id": 1,
"title": "Dawn of Justice"
}
To find the movie with the title Dawn of Justice, we can simply run
db.movies.find({ title: "Dawn of Justice" });
This command will give us an exact match for the provided string as it will translate to (in SQL terms)
select *
from movies
where title = "Dawn of Justice"
However, our users would not input search queries like this. They could enter something like _dawn of justice_, _Dawn of justice_, _DAWN OF JUSTICE_ or any non-exact search query.
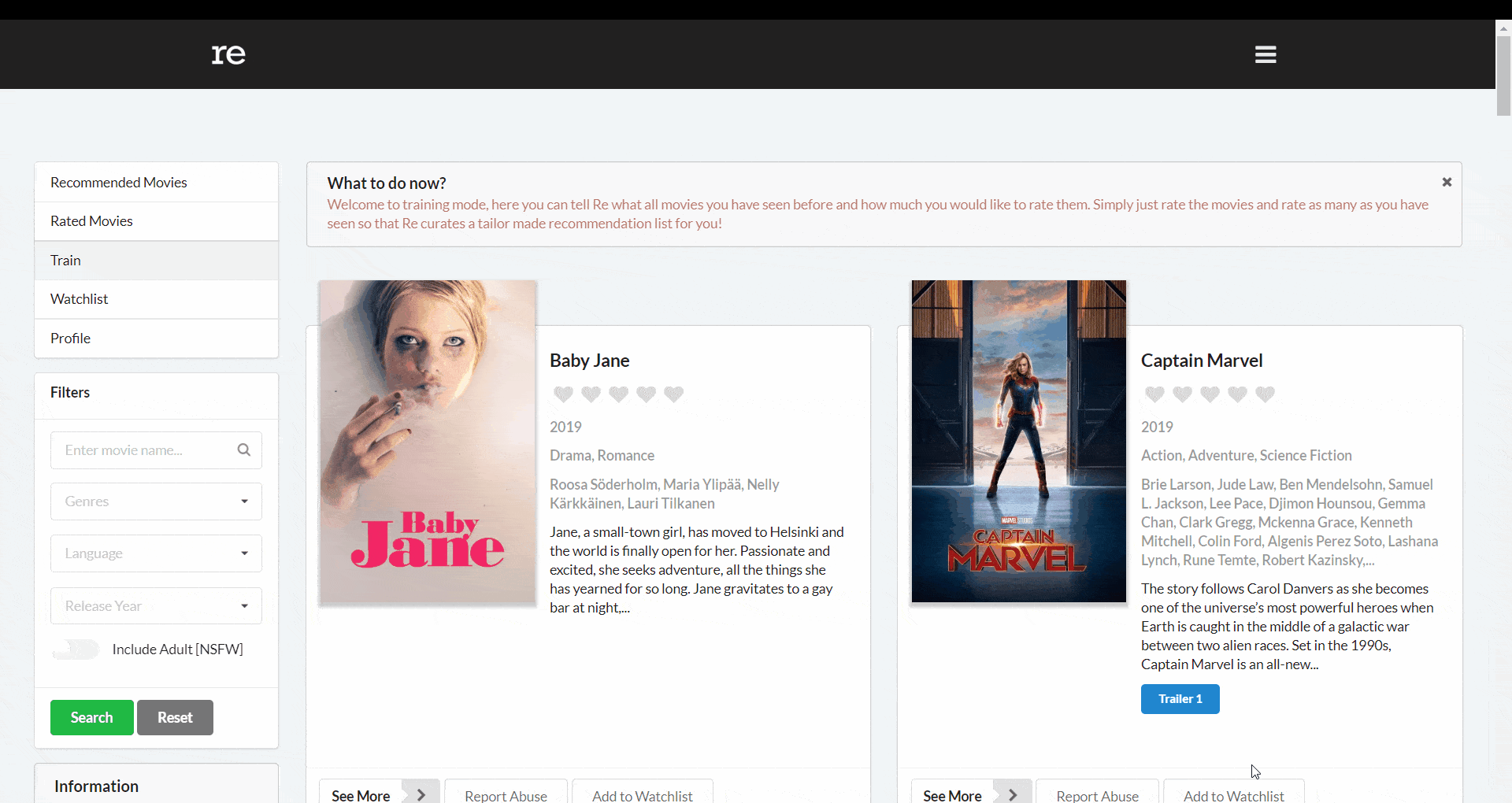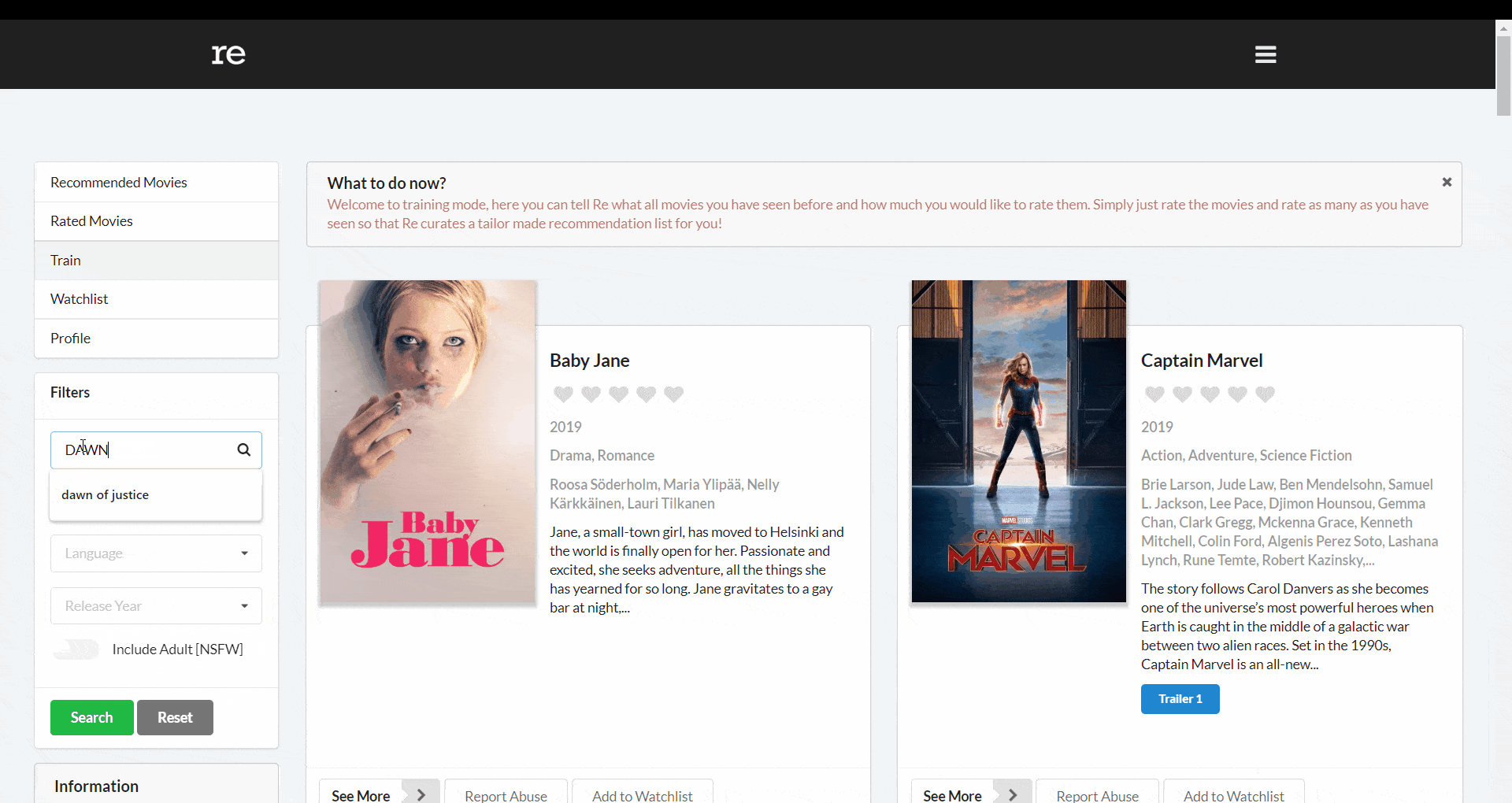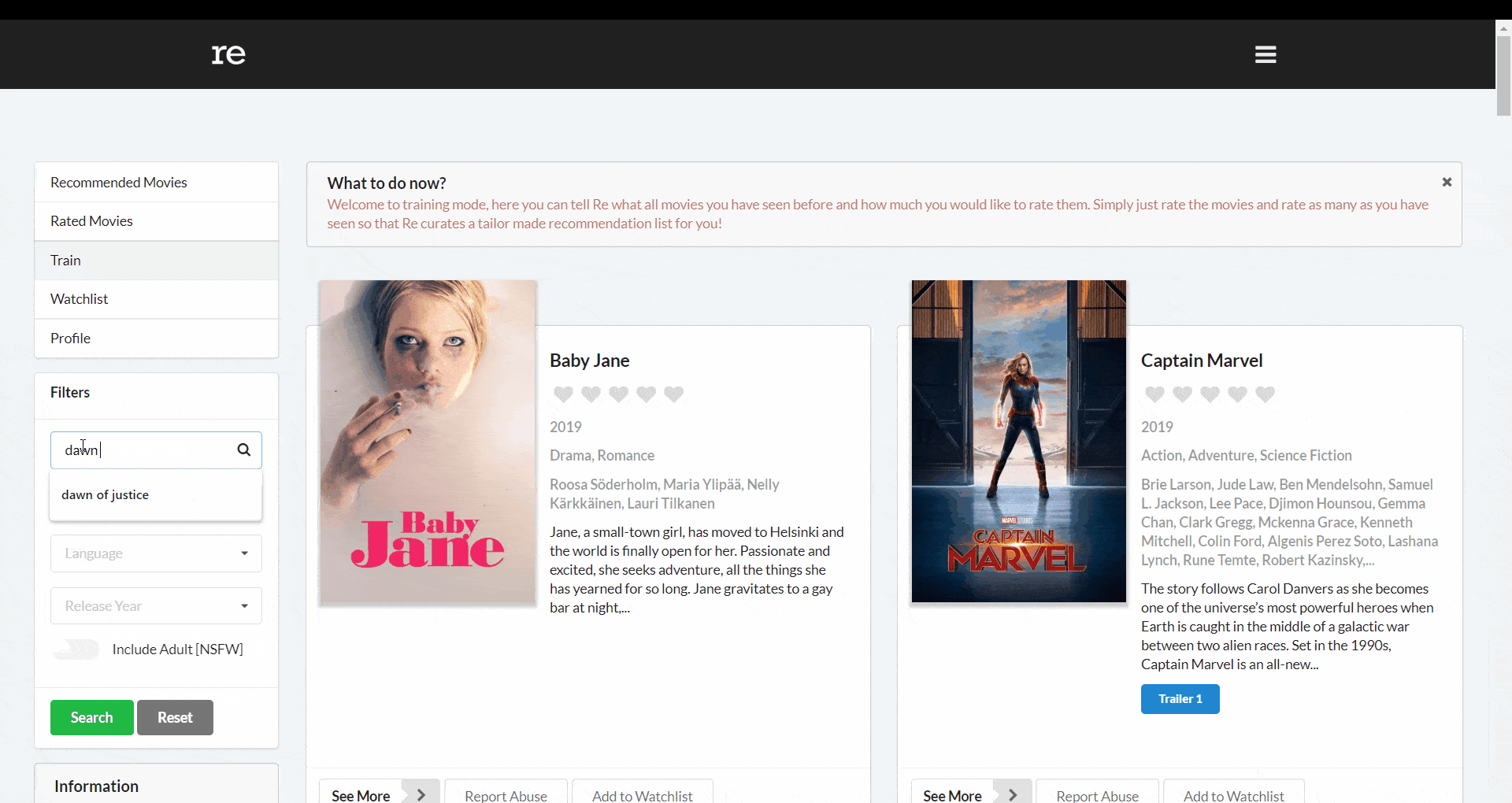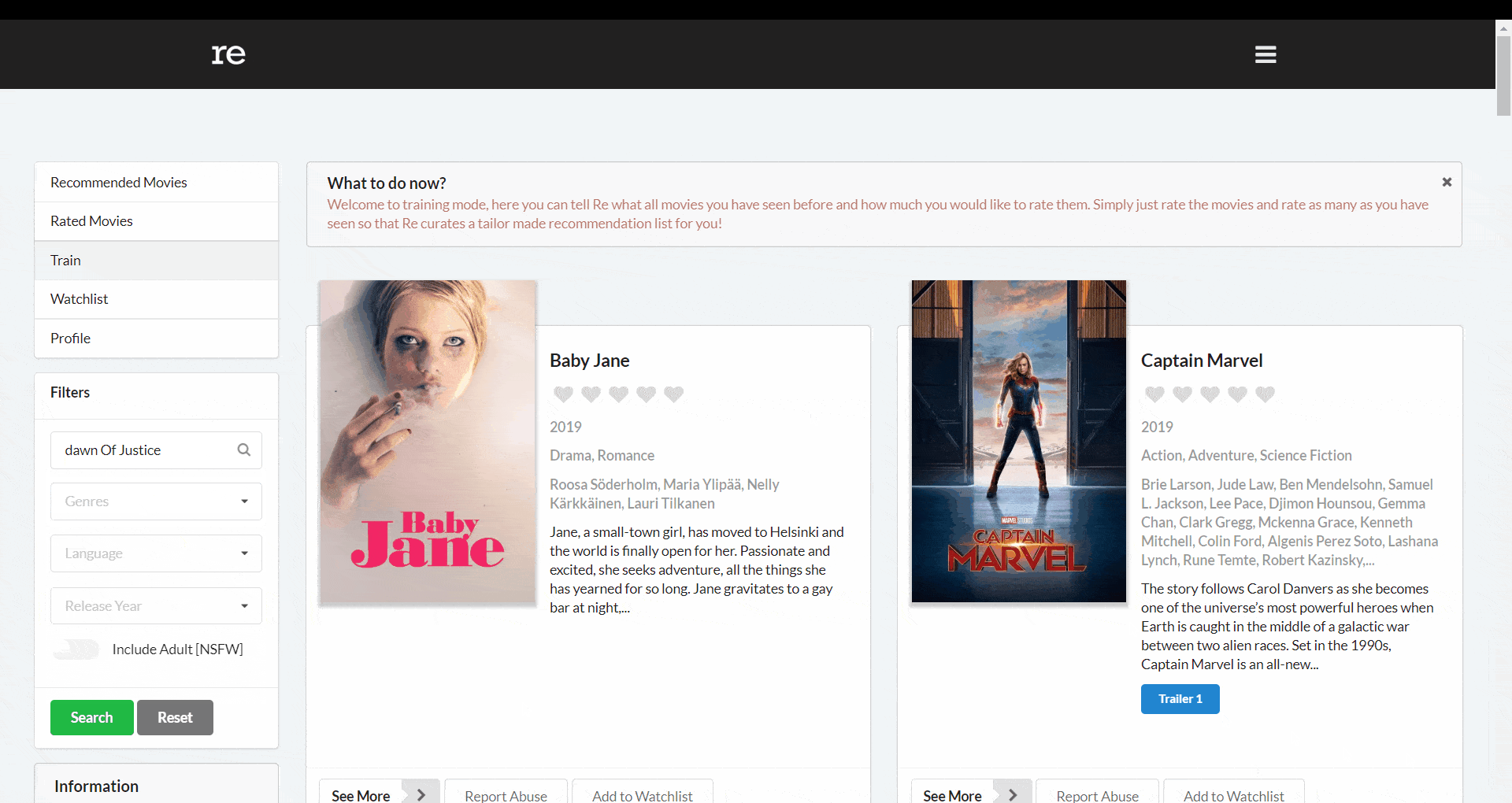
Here, _find()_ would not work. In such cases, we can use Regular Expressions (regex) which provides a way to match strings against a pattern and MongoDB comes with a built-in regex engine. We can use a query like below where i makes the regex case-insensitive.
db.movies.find({ title: /Dawn of Justice/i });
We can leave it to that but as soon as your database size grows, the fetch time of this query will increase and will consume a lot of CPU time.

As you can see in the above demonstration, due to the large size of the database, it takes more than 20 seconds to return the response for a simple search and users will not wait that long. So, what should we do now?
Text Indexes to the Rescue
Starting from version 2.4, MongoDB supports text indexes to search inside string content. A text index will tokenize and stem the content of the field as in it will break the string into individual words or tokens, and will further reduce them to their stems so that variants of the same word will match. For example, "talk" matching "talks", "talked" and "talking" as "talk" is a stem of all three. We can create a text index via
db.movies.createIndex({ title: "text" });
MongoDB provides a $text operator which we can use to query data:
db.movies.find({ title: { $text: { $search: "Dawn of Justice" } });
This will improve the speed but we will still not get the desired results.
Power of Text Search with Regular Expressions
We can use the $and operator provided by MongoDB to join Text Search with Regular Expressions. We apply logically and to first find a board resultset using Text Search and filter it out using Regular Expressions. If the first condition (text search) fails then regex won't work.
We can do this by creating a query like
db.movies.find({
$and: [
{
$text: {
$search: "Dawn of Justice",
},
},
{
title: {
$regex: /Dawn of Justice/i,
},
},
],
});
Here, we find a superset of all movies with the title containing the text we are searching for and then filter the resultset with a regex query. If text search yields no result then regex won't execute at all.
This combination will reduce fetch time and CPU load than using regex queries alone.
This is one of the ways to improve your database performance. I learned these optimizations while working on a side project, which is an ML-powered recommendation system. You can check it out here: re.yomeshgupta.com